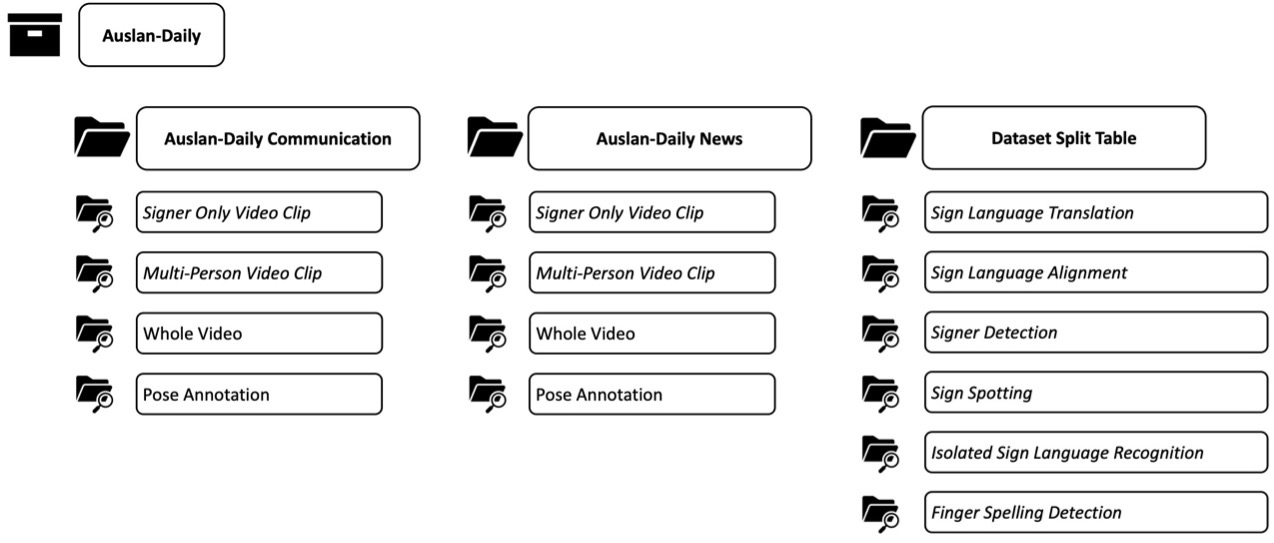
The two sub-datasets are stored separately:
Signer Only Video Clips: the sign video clips with cropping the signer regions based on the ground-truth bounding-boxes of the signers.
Multi-Person Video Clips: the sign video clips without cropping the acting signers.
Whole Video: original video of each episode.
Pose Annotation: The pose sequences of all individuals in each sign video clip.
The dataset split for each task is stored in the Data Split Table file, please read the accompanying ReadMe.txt file carefully.